
背景说明
众所周知, Seconds_Behind_Master 无法准确反应复制延迟. 为了准确的反应复制延迟, 业界的办法是, 创建一个延迟监控表, 周期性(往往是每秒)更新这个表的时间戳字段, 计算当前时间与该字段差值, 以此判断复制延迟. 典型的例子是Percona的pt-heartbeat. 另外TIDB DM也使用了相同的方法监控同步延迟.
在我们这里, 使用了主从和MGR两种架构集群, 为了更好地监控延迟, DBA开发了一个python脚本, 脚本从CMDB获取所有集群ProxySQL节点, 连接ProxySQL, 每秒更新dbms_monitor.monitor_delay表. 表结构和执行的语句为:
1 | root@localhost 13:23:42 [dbms_monitor]> show create table monitor_delay\G |
为了保证”每秒”更新, 脚本做了超时处理, 如果某个集群执行语句(连接超时/执行语句超时等)超时, 则抛出异常, sleep 一段时间(这个一段时间+ 本次循环已用时间=1s), 进入下次循环
问题产生
2021.10.14 15:45左右, DBA在rc环境进行演练, 部分集群宕机
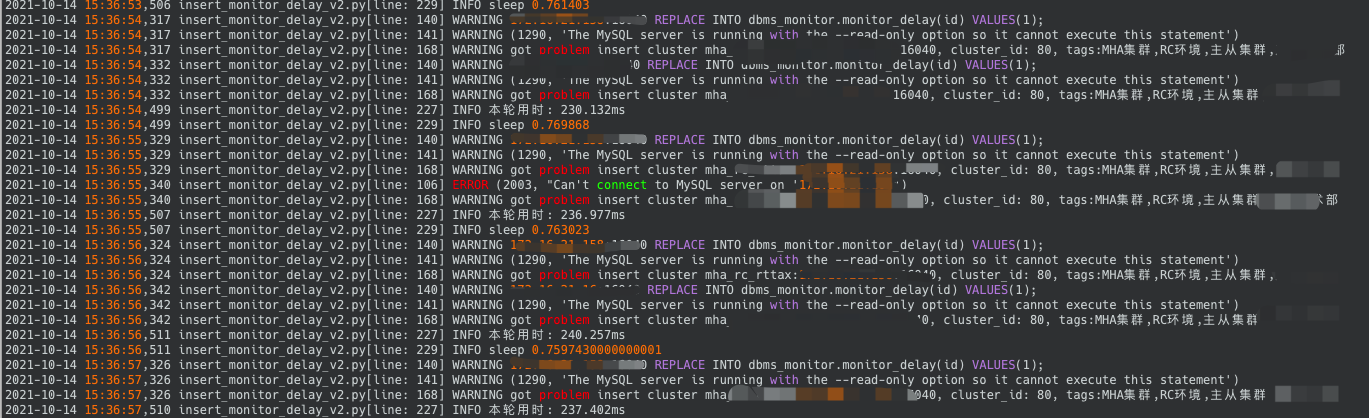
从脚本日志也可以看出, 部分rc集群异常
随后数据库cpu趋势监控报警
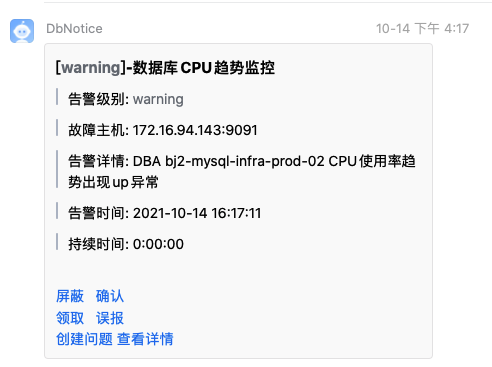
查看监控, 发现很多8核心服务器cpu使用率有明显上升
这部分服务器会采用多实例部署方式, 部署非核心业务集群, 往往比较空闲
DBA在经过一系列分析定位后排查后, 发现一个奇怪的现象:
- 关闭延迟监控脚本CPU使用率上升
- 开启延迟监控脚本CPU使用率下降
问题原因
定位占用CPU真凶
上面的现象奇怪就奇怪在与我们的通常认知相反; 如果是开启脚本CPU使用率上升, 关闭脚本CPU使用率下降还可以理解, 这种情况8成是脚本问题, 但实时情况是完全相反的
我们登录一个问题服务器, 选择一个mysql实例, 使用如下命令找到占用CPU高的mysql线程id
1 | pidstat -t -p 16904 1 |
如上所示, TID:17987 占用CPU高, 我们登录数据库查看这个线程在干什么
1 | fan@127.0.0.1 13:41:03 [(none)]> select * from performance_schema.threads where THREAD_OS_ID = 17987 \G |
如上所示, 这个线程是innodb后台线程page_cleaner_thread; page_cleaner_thread是用来刷脏页的
看到这里, 很自然的会认为是写操作过多, 导致频繁刷脏, 但事实是, 这些实例基本没有写入操作(通过分析binlog).
通过google 搜索 “page_cleaner High cpu usage”, 找到一篇阿里内核月报 MySQL · 引擎特性 · page cleaner 算法
这篇文章大致说的是, page cleaner的刷脏逻辑, 逻辑如下图所示
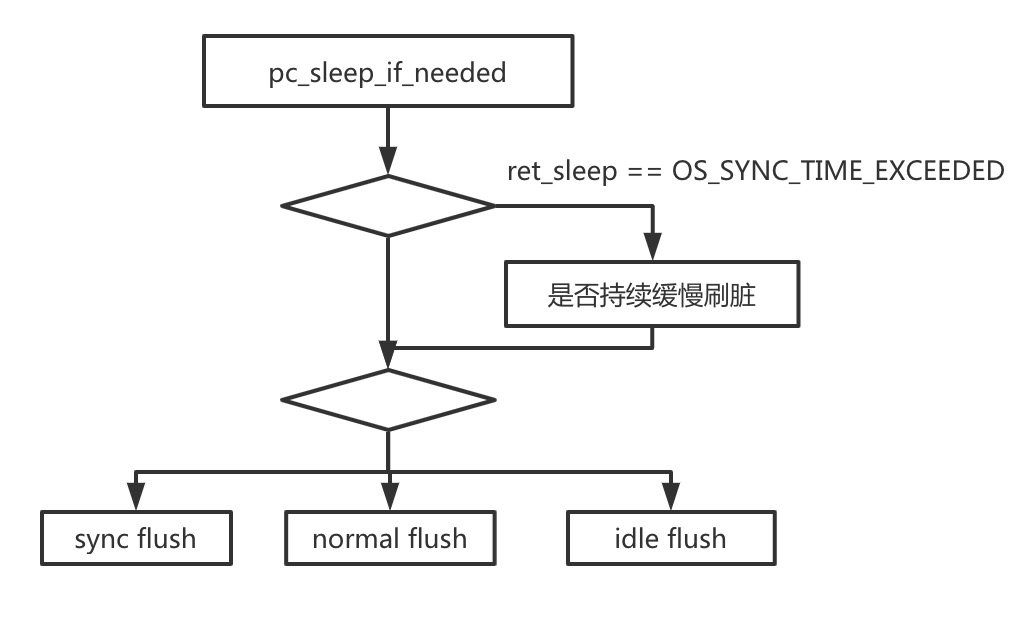
pc_sleep_if_needed
page cleaner 的循环刷脏周期是 1s,如果不足 1s 就需要 sleep,超过 1s 可能是刷脏太慢,不足 1s 可能是被其它线程唤醒的。
是否持续缓慢刷脏
错误日志里有时候会看到这样的日志:
Page cleaner took xx ms to flush xx and evict xx pages
这个表示上一轮刷脏进行的比较缓慢,首先 ret_sleep == OS_SYNC_TIME_EXCEEDED, 并且本轮刷脏和上一轮刷脏超过 3s,warn_interval 控制输出日志的频率,如果持续打日志,就要看看 IO 延迟了。
sync flush
Sync flush 不受 io_capacity/io_capacity_max 的限制,所以会对性能产生比较大的影响。
normal flush
当系统有负载的时候,为了避免频繁刷脏影响用户,会计算出每次刷脏的 page 数量
idle flush
系统空闲的时候不用担心刷脏影响用户线程,可以使用最大的 io_capacity 刷脏。RDS 有参数 srv_idle_flush_pct 控制刷脏比例,默认是 100%。
这里就是问题的关键:
- 系统空闲的时候不用担心刷脏影响用户线程,可以使用最大的 io_capacity 刷脏;
- 当系统有负载的时候,为了避免频繁刷脏影响用户,会计算出每次刷脏的 page 数量进行刷脏
看到这里我猜测, 当监控脚本启动时, innodb认为”系统有负载”, 采用normal flush方式刷脏页, 避免频繁刷脏影响用户; 当脚本关闭时, innodb认为系统空闲, 采用idle flush方式尽力刷脏
我在测试服务器, 使用 while true; do mysql -udbms_monitor_rw -psuperpass -h172.16.23.x -P3307 dbms_monitor -e”REPLACE INTO dbms_monitor.monitor_delay(id) VALUES(1)” ; sleep 1 ; done 模拟监控脚本每秒更新
测试服务器又N个实例, 就启动N个脚本, 保证每个实例每秒都有写入, 我这里有5个实例 3306-3310, 所以我开了5个窗口对每个实例运行上述命令
这样做也可以排除python脚本和proxysql
结果CPU使用率有明显下降
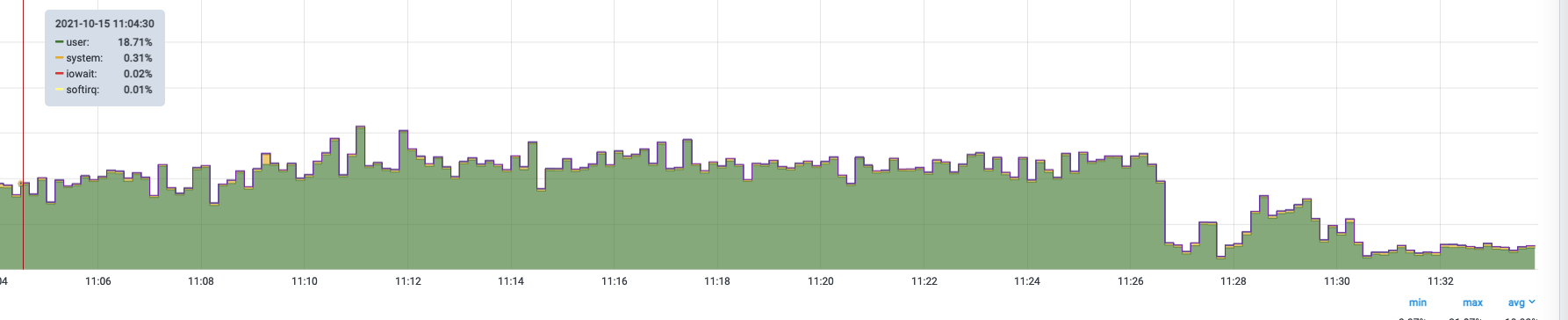
关闭脚本CPU使用率上升
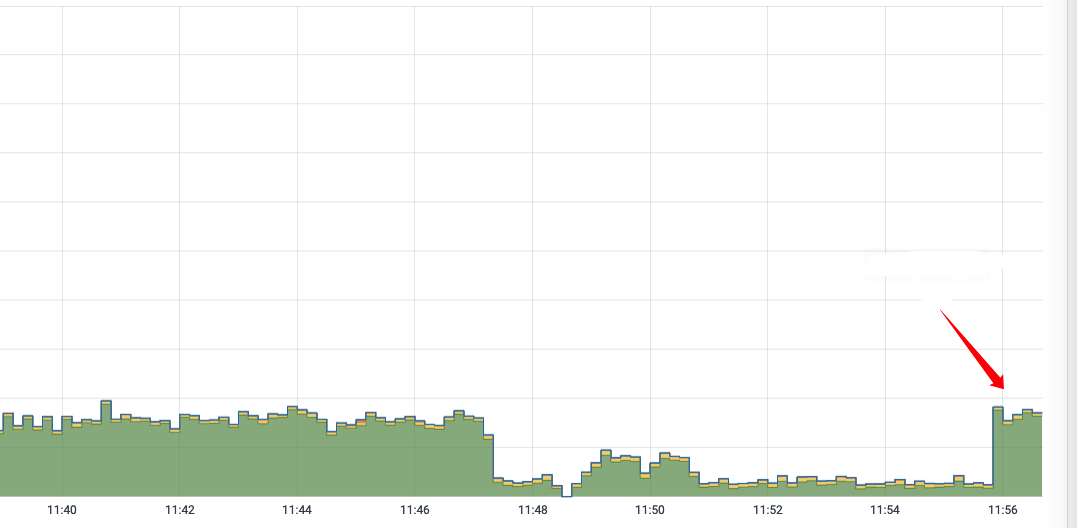
我们选取非核心业务节点测试, 也产生了相同的效果, 至此基本定位了问题发生原因
如何处理?
不需要处理.
在8.0版本增加了参数innodb_idle_flush_pct
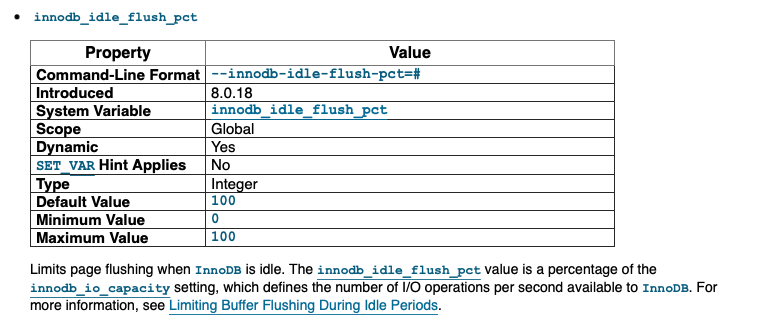
来控制idle flush模式下的刷脏量